The 150x Pgvector Speedup: A Year-in-Review
I wanted to write a “year-in-review” covering all the performance pgvector has made (with significant credit to Andrew Kane), highlighting specific areas where pgvector has improved (including one 150x improvement!) and areas where we can continue to do better.
A few weeks ago, I started outlining this post and began my data collection. While I was working on this over a two week period, no fewer than three competitive benchmarks against pgvector published. To me, this is a testament both how well pgvector is at handling vector workloads (and by extension, PostgreSQL too) that people are using it as the baseline to compare it to their vector search systems.
Some of these benchmarks did contain info that identified areas we can continue to improve both PostgreSQL and pgvector, but I was generally disappointed in the methodology used to make these comparisons. Of course I’d like to see pgvector perform well in benchmarks, but it’s important to position technologies fairly and be vocally self-critical on where your system can improve to build trust in what you’re building.
I have a separate blog post planned for how to best present benchmark studies between different systems for vector similarity search (it’s a topic I’m interested in). Today though, I want to compare pgvector against itself, and highlight areas it’s improved over the past year, and where the project can continue to go and grow.
How I ran these tests
An important aspect of any benchmark is transparency. First, I’ll discuss the test methodology I used, describe the test environment setup (instances, storage, database configuration), and then discuss the results. If you’re not interested in this part, you can skip ahead to “The 150x pgvector speedup”, but this information can help you with your own testing!
First, what are testing for? We’ll be looking at these specific attributes in these tests:
- Recall: A measurement of the relevancy of our results - what percentage of the expected results are returned during a vector search? Arguably, this is the most important measurement - it doesn’t matter if you have the highest query throughput if your recall is poor.
- Storage size: This could be related to storing your original vector/associated data, and any data you store in a vector index. Because PostgreSQL is a database, at a minimum you’ll have to store the vector in the table, and pay additional storage costs for building a vector index.
- Load time / index build time: How long does it take to load your vector data into an existing index? If your data is preloaded, how long does it take to build an index? Spending more time building your index can help improve both recall and query performance, but this is often the most expensive part of a vector database and can impact overall system performance.
- Latency (p99): Specifically, how long it takes to return a single result, but representing the 99th percentile (“very slow”) queries. This serves as an “upper bound” on latency times.
- Single-connection Throughput / queries per second (QPS): How many queries can be executed each second? This impacts how much load you can put on a single system.
(More on the “single-connection” distinction in a future blog post).
This is a “year-in-review” post, so I ran tests against the following releases and configurations of pgvector. I’m including the shorthand that I’ll show in the tests results.
| pgvector version | Index type | Test name (r7gd) | Test name (r7i) | Notes |
|---|---|---|---|---|
| 0.4.1 | IVFFlat | r7gd.041 | r7i.041 | |
| 0.4.4 | IVFFlat | r7gd.044 | r7i.044 | |
| 0.5.0 | HNSW | r7gd.050 | r7i.050 | |
| 0.5.1 | HNSW | r7gd.051 | r7i.051 | |
| 0.6.0 | HNSW | r7gd.060 | r7i.060 | |
| 0.6.2 | HNSW | r7gd.062 | r7i.062 | |
| 0.7.0 | HNSW | r7gd.070 | r7i.070 | |
| 0.7.0 | HNSW - SQ16 | r7gd.070.fp16 | r7i.070.fp16 | Stores 2-byte float representation of vectors in the index |
| 0.7.0 | HNSW - BQ + Jaccard rerank | r7gd.070.bq-jaccard-rerank | r7i.070.bq-jaccard-rerank | Stores binary representation of vectors in index using Jaccard distance; results are re-ranked using original vector after the index search |
| 0.7.0 | HNSW - BQ + Hamming rerank | r7gd.070.bq-jaccard-rerank | r7i.070.bq-jaccard-rerank | Stores binary representation of vectors in index using Hamming distance; results are re-ranked using original vector after the index search |
Test setup
To simplify the comparison, I kept the index build parameters the same for all of the tests. Adjusting build parameters can impact all five of the key metrics (please see previous posts and talks), but the purpose of this blog post is to show how pgvector has evolved over the past year and choosing a fixed set of parameters does serve to show how it’s improved and where it can grow. Below are the build parameters used for each index type:
| Index type | Build parameters |
|---|---|
| IVFFlat | lists: 1000 |
| HNSW | m: 16; ef_construction: 256 |
For the testing, I used a r7gd.16xlarge and a r7i.16xlarge, both of which have 64 vCPU and 512GiB of RAM. I stored the data on the local NVMe on the r7gd, and on gp3 storage for the r7i. If this test was looking at behaviors around storage, that fact would matter heavily, but these tests focused specifically on CPU and memory characteristics.
For these tests, I used PostgreSQL 16.2 (aside: the upcoming PostgreSQL 17 release is expected to have the ability to utilize AVX-512 SIMD instructions for the pg_popcount function, used by the Jaccard distance; this doesn’t account for those optimizations) with the following configurations, using parallelism where available:
| checkpoint_timeout | 2h |
| effective_cache_size | 256GB |
| jit | off |
| maintenance_work_mem | 64GB |
| max_parallel_maintenance_workers | 63 |
| max_parallel_workers | 64 |
| max_parallel_workers_per_gather | 64 |
| max_wal_size | 20GB |
| max_worker_processes | 128 |
| shared_buffers | 128GB |
| wal_compression | zstd |
| work_mem | 64MB |
I used the ANN Benchmark framework to run the tests. I made the following modifications to the pgvector module:
- I commented out the
subprocess.runline so I could run the test in a local process, not a container - I added modules to run both the new work scalar/binary quantization code in v0.7.0 (see previous blog post for more details). This followed the same format as the existing test.
- Additionally, I revived the IVFFlat code to run those tests. I did include a recent commit to accelerate the loading of data into the table.
- I did make a small tweak to the timing of the index build. Instead of considering both the data load and the index build time, I only timed the index build. I’m planning to propose this as a contribution to the upstream project, as the primary goal of the
fitportion of ANN Benchmarks is to test the index build time.
For each index type I used the following search parameters, which are the defaults for what’s in the pgvector module for ANN Benchmarks:
| Index type | Search parameters |
|---|---|
| IVFFlat | ivfflat.probes: [1, 2, 4, 10, 20, 40, 100] |
| HNSW | hnsw.ef_search: [10, 20, 40, 80, 120, 200, 400, 800] |
Finally, the test results below will show the recall target (e.g. 0.90 or 90%). The results are shown at the threshold that each test passed that recall level (if it passed that recall level). I could probably have fine tuned this further to find the exact hnsw.ef_search value where the test crossed the threshold, which would give a more accurate representation of the performance characteristics at a recall target, but again, the main goal is to show the growth and growth areas of pgvector over the past year.
And now it’s time for…
The 150x pgvector speedup
For the first test, we’ll review the results from the dbpedia-openai-1000k-angular benchmark at 99% recall. The results are below:
dbpedia-openai-1000k-angular @ 99% recall on a r7gd.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7gd.041 | 0.994 | 8 | 1 | 150.16 | 1 | 474 | 16 | 7.56 | 1 |
| r7gd.044 | 0.994 | 8 | 1 | 155.25 | 1 | 476 | 16 | 7.56 | 1 |
| r7gd.050 | 0.993 | 243 | 30.4 | 5.74 | 27 | 7479 | 1 | 7.55 | 1 |
| r7gd.051 | 0.992 | 247 | 30.9 | 5.67 | 27.4 | 5088 | 2 | 7.55 | 1 |
| r7gd.060 | 0.992 | 252 | 31.5 | 5.52 | 28.1 | 253 | 30 | 7.55 | 1 |
| r7gd.062 | 0.992 | 253 | 31.6 | 5.54 | 28 | 252 | 30 | 7.55 | 1 |
| r7gd.070 | 0.992 | 253 | 31.6 | 5.51 | 28.2 | 250 | 30 | 7.55 | 1 |
| r7gd.070.fp16 | 0.993 | 263 | 32.9 | 5.3 | 29.3 | 146 | 51 | 3.78 | 2 |
| r7gd.070.bq-hamming-rerank | 0.99 | 236 | 29.5 | 5.4 | 28.8 | 49 | 153 | 0.46 | 16.4 |
| r7gd.070.bq-jaccard-rerank | 0.99 | 234 | 29.3 | 5.38 | 28.9 | 50 | 150 | 0.46 | 16.4 |
And there it is: between pgvector 0.5.0 (where HNSW was introduced) and pgvector 0.7.0, we see that we can get a 150x speedup in the index build time when we use the “binary quantization” methods. Note that we can’t always use binary quantization with our data, but we can see we can that scalar quantization to 2-byte floats show over a 50x speedup from the initial HNSW implementation in pgvector 0.5.0. A lot of this speedup is attributed to the use of parallel workers (in this case, 64) during the index build process. For fun, here’s how this looks in a bar chart:
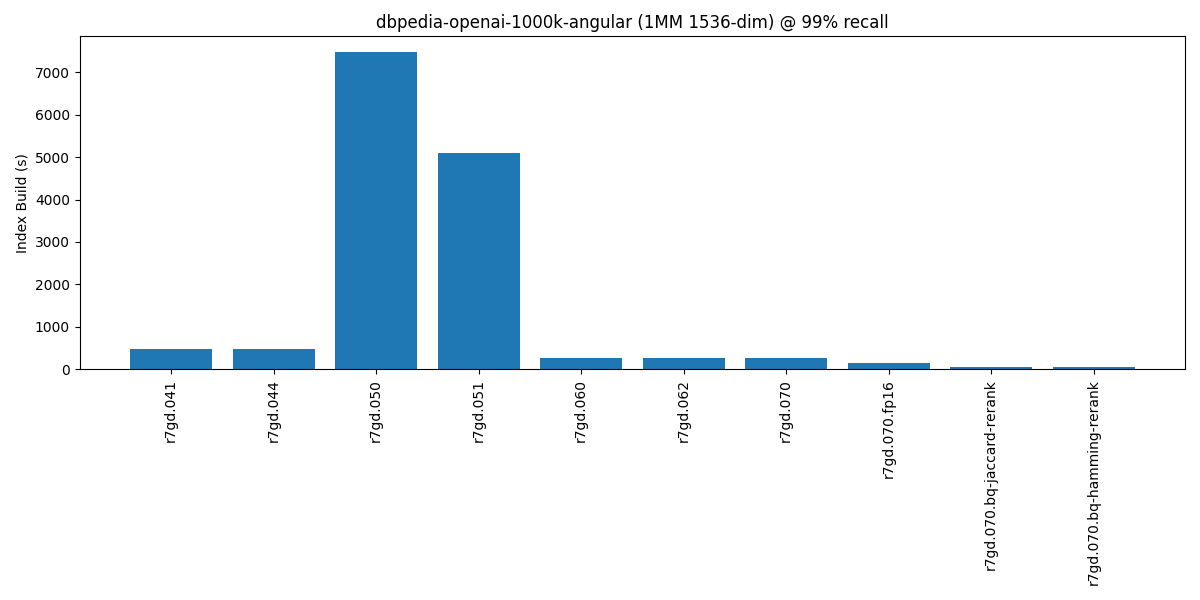
(Note: I do chuckle a bit, as it reminds of a time I fixed a query I wrote to get a 100x speedup. It was a recursive query, but I used UNION ALL when instead I wanted UNION. Unlike my goofy mistake, this I do take this work in pgvector to be a bona fide speedup due to all of the improvements in the pgvector implementation).
Additionally, we see that the addition of HNSW allows us to get a 30x QPS boost and an almost 30x p99 latency boost over IVFFlat at 99% recall. Queries were executed serially; we’d need to run additional tests to see how pgvector scales with client concurrently querying the data.
dbpedia-openai-1000k-angular @ 99% recall on a r7i.16xlarge
Different CPU families can impact the results from a test based upon the availability of acceleration instructions (e.g. SIMD). pgvector 0.7.0 added support for SIMD disaptching functions on x86-64 architecture, so it’s important to test what impact this has on our test runs. For these tests, I used an Ubuntu 22.04, with the pgvector code compiled with gcc 12.3 and clang-15, and am showing the results from the dbpedia-openai-1000k-angular benchmark at 99% recall:
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7i.041 | 0.994 | 8 | 1 | 153.01 | 1 | 496 | 15.0 | 7.56 | 1 |
| r7i.044 | 0.994 | 8 | 1 | 156.58 | 1 | 494 | 15.1 | 7.56 | 1 |
| r7i.050 | 0.992 | 255 | 31.9 | 5.42 | 28.9 | 7443 | 1.0 | 7.55 | 1 |
| r7i.051 | 0.992 | 245 | 30.6 | 5.66 | 27.7 | 5201 | 1.4 | 7.55 | 1 |
| r7i.060 | 0.992 | 261 | 32.6 | 5.28 | 29.7 | 773 | 9.6 | 7.55 | 1 |
| r7i.062 | 0.992 | 265 | 33.1 | 5.22 | 30.0 | 382 | 19.5 | 7.55 | 1 |
| r7i.070 | 0.993 | 255 | 31.9 | 5.40 | 29.0 | 388 | 19.2 | 7.55 | 1 |
| r7i.070.fp16 | 0.993 | 282 | 35.3 | 4.87 | 32.2 | 227 | 32.8 | 3.78 | 2 |
| r7i.070.bq-hamming-rerank | 0.99 | 269 | 33.6 | 4.78 | 32.8 | 64 | 116.3 | 0.46 | 16.4 |
| r7i.070.bq-jaccard-rerank | 0.99 | 267 | 33.4 | 4.77 | 32.8 | 66 | 112.8 | 0.46 | 16.4 |
Again, we see a 100x+ speedup in index build time when using the “binary quantization” methods, and comparable performance results overall to what we had with the r7gd family. We can also see a more than 30x improvement in both throughput and latency as well. Here is a chart that shows how the index build times have decreased on the r7i:
(I’ll note here I really need to level up my matplotlib skills; likely Excel too, as it was taking me awhile to get the data charted there. Anyway, this is all the charting I’m doing in this blog post).
As explored in the previous blog post on scalar and binary quantization, we can’t always use binary quantization and achieve our recall target due to lack of bit diversity in the indexed vectors. We saw this with both the sift-128-euclidean and gist-960-euclidean datasets. However, both still have nice speedups over the course of the year.
Below are the results from the sift-128-euclidean benchmark @ 99% recall on both architectures:
sift-128-euclidean @ 99% recall on a r7gd.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7gd.041 | 0.999 | 33 | 1.0 | 44.05 | 1.0 | 58 | 41.6 | 0.51 | 1.5 |
| r7gd.044 | 0.999 | 33 | 1.0 | 42.39 | 1.0 | 59 | 40.9 | 0.51 | 1.5 |
| r7gd.050 | 0.994 | 432 | 13.1 | 2.98 | 14.8 | 2411 | 1.0 | 0.76 | 1.0 |
| r7gd.051 | 0.994 | 432 | 13.1 | 2.98 | 14.8 | 1933 | 1.2 | 0.76 | 1.0 |
| r7gd.060 | 0.994 | 453 | 13.7 | 2.84 | 15.5 | 67 | 36.0 | 0.76 | 1.0 |
| r7gd.062 | 0.994 | 458 | 13.9 | 2.81 | 15.7 | 57 | 42.3 | 0.76 | 1.0 |
| r7gd.070 | 0.994 | 487 | 14.8 | 2.65 | 16.6 | 56 | 43.1 | 0.76 | 1.0 |
| r7gd.070.fp16 | 0.994 | 482 | 14.6 | 2.68 | 16.4 | 48 | 50.2 | 0.52 | 1.5 |
sift-128-euclidean @ 99% recall on a r7i.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7i.041 | 0.999 | 31 | 1.1 | 48.57 | 1.1 | 43 | 51.3 | 0.51 | 1.5 |
| r7i.044 | 0.999 | 29 | 1.0 | 51.34 | 1.0 | 44 | 50.2 | 0.51 | 1.5 |
| r7i.050 | 0.994 | 436 | 15.0 | 2.96 | 17.3 | 2208 | 1.0 | 0.76 | 1.0 |
| r7i.051 | 0.994 | 426 | 14.7 | 3.06 | 16.8 | 1722 | 1.3 | 0.76 | 1.0 |
| r7i.060 | 0.994 | 503 | 17.3 | 2.57 | 20.0 | 581 | 3.8 | 0.76 | 1.0 |
| r7i.062 | 0.994 | 497 | 17.1 | 2.57 | 20.0 | 74 | 29.8 | 0.76 | 1.0 |
| r7i.070 | 0.994 | 492 | 17.0 | 2.60 | 19.7 | 74 | 29.8 | 0.76 | 1.0 |
| r7i.070.fp16 | 0.994 | 544 | 18.8 | 2.36 | 21.8 | 62 | 35.6 | 0.52 | 1.5 |
Across the board, there are some nice speedups, including the 50x index build time improvement for the quantized halfvec test (r7gd.070.fp16), similar to the dbpedia-openai-1000k-angular test.
Let’s take a quick look at the gist-960-euclidean data. With the previous tests, we looked at the results targeting 99% recall, as the QPS/p99 speedups were more pronounced with those. However, gist-960-euclidean tends to be particularly challenging to get good throughput/performance results at high recall (though with binary quantization, I can get over 6,000 QPS at 0% recall!), and interestingly I observed the best speedups at 90% recall.
gist-960-euclidean @ 90% recall on a r7gd.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7gd.041 | 0.965 | 13 | 1.0 | 128.91 | 1.0 | 300 | 22.6 | 3.82 | 2.0 |
| r7gd.044 | 0.968 | 14 | 1.1 | 123.66 | 1.0 | 297 | 22.9 | 3.82 | 2.0 |
| r7gd.050 | 0.923 | 215 | 16.5 | 5.53 | 23.3 | 6787 | 1.0 | 7.50 | 1.0 |
| r7gd.051 | 0.924 | 215 | 16.5 | 5.59 | 23.1 | 4687 | 1.4 | 7.50 | 1.0 |
| r7gd.060 | 0.924 | 229 | 17.6 | 5.16 | 25.0 | 204 | 33.3 | 7.50 | 1.0 |
| r7gd.062 | 0.923 | 224 | 17.2 | 5.31 | 24.3 | 198 | 34.3 | 7.50 | 1.0 |
| r7gd.070 | 0.922 | 229 | 17.6 | 5.18 | 24.9 | 197 | 34.5 | 7.50 | 1.0 |
| r7gd.070.fp16 | 0.921 | 248 | 19.1 | 4.83 | 26.7 | 137 | 49.5 | 2.50 | 3.0 |
gist-960-euclidean @ 90% recall on a r7i.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7i.041 | 0.966 | 16 | 1.1 | 111.47 | 1.1 | 282 | 22.2 | 3.82 | 2.0 |
| r7i.044 | 0.965 | 15 | 1.0 | 120.90 | 1.0 | 289 | 21.7 | 3.82 | 2.0 |
| r7i.050 | 0.923 | 226 | 15.1 | 5.20 | 23.3 | 6273 | 1.0 | 7.50 | 1.0 |
| r7i.051 | 0.925 | 228 | 15.2 | 5.26 | 23.0 | 4212 | 1.5 | 7.50 | 1.0 |
| r7i.060 | 0.924 | 246 | 16.4 | 4.84 | 25.0 | 1109 | 5.7 | 7.50 | 1.0 |
| r7i.062 | 0.923 | 245 | 16.3 | 4.88 | 24.8 | 301 | 20.8 | 7.50 | 1.0 |
| r7i.070 | 0.924 | 238 | 15.9 | 4.97 | 24.3 | 295 | 21.3 | 7.50 | 1.0 |
| r7i.070.fp16 | 0.921 | 271 | 18.1 | 4.33 | 27.9 | 180 | 34.9 | 2.50 | 3.0 |
Again, we can see the effects of parallelism on speeding up the HNSW builds, as well as the effects on shrinking the index size by using 2-byte floats. Also, similar to the sift-128-euclidean test, we’re unable to use binary quantization to achieve 90% recall.
For completeness, here are a few more sets of results. I chose the “recall” values to optimize for where I saw the biggest performance gains:
glove-25-angular @ 99% recall on a r7gd.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7gd.041 | 0.997 | 26 | 1.0 | 53.50 | 1.0 | 31 | 81.9 | 0.14 | 3.2 |
| r7gd.044 | 0.997 | 26 | 1.0 | 53.98 | 1.0 | 33 | 76.9 | 0.14 | 3.2 |
| r7gd.050 | 0.995 | 493 | 19.0 | 2.64 | 20.4 | 2538 | 1.0 | 0.45 | 1.0 |
| r7gd.051 | 0.995 | 495 | 19.0 | 2.64 | 20.4 | 1922 | 1.3 | 0.45 | 1.0 |
| r7gd.060 | 0.995 | 514 | 19.8 | 2.55 | 21.2 | 53 | 47.9 | 0.45 | 1.0 |
| r7gd.062 | 0.995 | 470 | 18.1 | 2.79 | 19.3 | 49 | 51.8 | 0.45 | 1.0 |
| r7gd.070 | 0.995 | 522 | 20.1 | 2.50 | 21.6 | 48 | 52.9 | 0.45 | 1.0 |
| r7gd.070.fp16 | 0.995 | 521 | 20.0 | 2.51 | 21.5 | 48 | 52.9 | 0.40 | 1.1 |
glove-25-angular @ 99% recall on a r7i.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7i.041 | 0.997 | 23 | 1.0 | 59.08 | 1.0 | 38 | 63.5 | 0.14 | 3.2 |
| r7i.044 | 0.997 | 24 | 1.0 | 59.59 | 1.0 | 30 | 80.5 | 0.14 | 3.2 |
| r7i.050 | 0.995 | 539 | 23.4 | 2.41 | 24.7 | 2414 | 1.0 | 0.45 | 1.0 |
| r7i.051 | 0.995 | 545 | 23.7 | 2.39 | 24.9 | 1827 | 1.3 | 0.45 | 1.0 |
| r7i.060 | 0.995 | 557 | 24.2 | 2.34 | 25.5 | 471 | 5.1 | 0.45 | 1.0 |
| r7i.062 | 0.995 | 574 | 25.0 | 2.27 | 26.3 | 64 | 37.7 | 0.45 | 1.0 |
| r7i.070 | 0.995 | 569 | 24.7 | 2.28 | 26.1 | 63 | 38.3 | 0.45 | 1.0 |
| r7i.070.fp16 | 0.995 | 569 | 24.7 | 2.28 | 26.1 | 60 | 40.2 | 0.40 | 1.1 |
The interesting thing about both of these tests is that the IVFFlat index builds are both faster and smaller than the HNSW index builds - and that is without using any parallelism during the IVFFlat build. However, the HNSW numbers show a sigificant boost in throughput and p99 latency.
Finally, here are the results from the glove-100-angular test. In my test, I wasn’t able to get much above 95% recall. I would likely need to increase the m build parameter to get towards 99% recall, but as mentioned earlier, the goal of this testing was primarily to see how pgvector has improved over the course of the year and not optimize parameters for a particular dataset:
glove-100-angular @ 95% recall on a r7gd.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7gd.041 | 0.963 | 29 | 1.0 | 47.10 | 1.0 | 68 | 58.0 | 0.48 | 1.7 |
| r7gd.044 | 0.963 | 29 | 1.0 | 46.20 | 1.0 | 69 | 57.1 | 0.48 | 1.7 |
| r7gd.050 | 0.965 | 65 | 2.2 | 21.05 | 2.2 | 3941 | 1.0 | 0.82 | 1.0 |
| r7gd.051 | 0.965 | 65 | 2.2 | 20.90 | 2.3 | 2965 | 1.3 | 0.82 | 1.0 |
| r7gd.060 | 0.965 | 63 | 2.2 | 21.22 | 2.2 | 83 | 47.5 | 0.82 | 1.0 |
| r7gd.062 | 0.965 | 62 | 2.1 | 21.68 | 2.2 | 78 | 50.5 | 0.82 | 1.0 |
| r7gd.070 | 0.965 | 66 | 2.3 | 20.07 | 2.3 | 77 | 51.2 | 0.82 | 1.0 |
| r7gd.070.fp16 | 0.965 | 67 | 2.3 | 19.97 | 2.4 | 68 | 58.0 | 0.57 | 1.4 |
glove-100-angular @ 95% recall on a r7i.16xlarge
| Test | Recall | Single Connection Throughput (QPS) | QPS Speedup | p99 Latency (ms) | p99 Speedup | Index Build (s) | Index Build Speedup | Index Size (GiB) | Size Improvement |
|---|---|---|---|---|---|---|---|---|---|
| r7i.041 | 0.963 | 27 | 1.0 | 50.43 | 1.0 | 53 | 66.8 | 0.48 | 1.7 |
| r7i.044 | 0.962 | 26 | 1.0 | 52.13 | 1.0 | 56 | 63.3 | 0.48 | 1.7 |
| r7i.050 | 0.965 | 81 | 3.1 | 16.70 | 3.1 | 3543 | 1.0 | 0.82 | 1.0 |
| r7i.051 | 0.965 | 82 | 3.2 | 16.49 | 3.2 | 2517 | 1.4 | 0.82 | 1.0 |
| r7i.060 | 0.965 | 79 | 3.0 | 16.64 | 3.1 | 692 | 5.1 | 0.82 | 1.0 |
| r7i.062 | 0.965 | 83 | 3.2 | 15.90 | 3.3 | 98 | 36.2 | 0.82 | 1.0 |
| r7i.070 | 0.965 | 81 | 3.1 | 16.27 | 3.2 | 95 | 37.3 | 0.82 | 1.0 |
| r7i.070.fp16 | 0.965 | 86 | 3.3 | 15.27 | 3.4 | 84 | 42.2 | 0.57 | 1.4 |
Overall with glove-100-angular on the selected build parameters, there are definite speedups on build times for HNSW indexes, and we do see improvements in throughput/latency. For this specific dataset, I’d recommend rerunning it with different HNSW build parameters to see if we can improve query performance numbers at higher levels of recall, but that’s an experiment for another day.
Where do we go from here?
It’s been quite a year for pgvector on many fronts, not to say the least the many people who are already building amazing apps with it today! A “billion-scale” vector storage problem is attainable with pgvector today, much of this attributed to the work of the last year. And while I can’t say enough about the work Andrew Kane has done on pgvector, I do want to give mentions to Heikki Linnakangas, Nathan Bossart, Pavel Borisov, and Arda Aytekin who all made contributions to improve pgvector performance (and apologies if I missed someone).
However, much like the almost 40-year-old database PostgreSQL, there are still ways pgvector can continue to grow. I’m going to talk more in depth about some longer term goals to better support vector workloads with pgvector and PostgreSQL at PGConf.dev 2024, but I’ll give a brief preview here.
Over the past year, pgvector has made significant gains across the board in index build times, index sizes, throughput, and latency, particularly on vector queries over an entire vector data set. Simplifying filtering (aka the WHERE clause) - pgvector and PostgreSQL already support this, but there are some areas we can make it easier and more efficient. Additionally, there are other search patterns that are gaining popularity, such as “hybrid search” like using simultaneously vector similarity search and fulltext search to return results. Again, this is something already supported by PostgreSQL natively, but there are areas we can simplify this process with pgvector. We’re seeing more work in pgvector to support hardware acceleration; this combined with further optimizations on And finally, there are some areas of PostgresQL we can prove to better support distributed pgvector workloads, but I’ll still emphasize that most workloads that involve PostgreSQL and pgvector will scale vertically (which means showing more concurrency testing!).
We’ll also have to see how vector search workloads evolve, as that will also dictate what new features we’ll see in pgvector. Please keep giving feedback on what you’re building with pgvector and how your experience is - as that is how we can continue to make the project better!