Distributed Queries for Pgvector
The past few releases of pgvector have emphasized features that help to vertically scale, particularly around index build parallelism. Scaling vertically is convenient for many reasons, especially because it’s simpler to continue managing data that’s located within a single instance.
Performance of querying vector data tends to be memory-bound, meaning that the more vector data you can keep in memory, the faster your database will return queries. It’s also completely acceptable to not have your entire vector workload contained within memory, as long as you’re meeting your latency requirements.
However, they may be a point that you can’t vertically scale any further, such as not having an instance large enough to keep your entire vector dataset in memory. However, there may be a way to combine PostgreSQL features with pgvector to create a multi-node system to run distributed, performant queries across multiple instances.
To see how this works, we’ll need to explore several features in PostgreSQL that help with segmenting and distributing data, including partitioning and foreign data wrappers. We’ll see how we can use these features to run distributed queries with pgvector, and explore the “can we” / “should we” questions.
Partitioning and pgvector
Partitioning is a general database technique that lets you divide data in a single table over multiple tables, and is used for purposes such as archiving, segmenting by time, and reducing the overall portion of a data set that you need to search over. PostgreSQL supports three types of partitioning: range, list, and hash. You use list and range partitioning when you have a defined partition key (e.g. company_id or start_date BETWEEN '2024-03-01' AND '2024-03-31), whereas you use hash partitioning when you want to evenly distribute your data across partitions.
There are many considerations you must make before adopting a partitioning strategy, including understanding how your application will interact with your partitioned table and your partition management strategy. You also want to ensure you don’t create “too many partitions,” which is an upper bound that’s increased over the past several PostgreSQL releases (1000s is acceptable, depending on strategy).
pgvector works natively with PostgreSQL partitioning. Based upon the structure of your data and query patterns, you may choose to partition your data and build individual indexes over each partition as a way to enable “prefiltering” (your WHERE clause) of your queries, for example:
CREATE TABLE documents (
id int,
category_id int,
embedding vector(1536)
) PARTITION BY HASH(category_id);
CREATE TABLE documents_0 PARTITION OF documents
FOR VALUES WITH (MODULUS 2, REMAINDER 0);
CREATE TABLE documents_1 PARTITION OF documents
FOR VALUES WITH (MODULUS 2, REMAINDER 1);
-- recursively creates an index on each partition
CREATE INDEX ON documents USING hnsw(embeddings vector_cosine_ops);
However, the above example also shows one of the challenges with partitioning if you’re searching over a partition with either mixed data in your filter, or with multiple filters. Based on your search parameter value (hnsw.ef_search or ivfflat.probes), you may not return enough results from the index that match all of the filters. You can remedy this by increasing the values of hnsw.ef_search or ivfflat.probes; as of this writing, there is also work going into pgvector to add more prefiltering options.
Now that we’ve had a brief overview of partitioning, let’s look at foreign data wrappers.
Foreign data wrappers and postgres_fdw
Foreign data wrappers (FDWs), part of the SQL/MED standard, let you work with remote data sources from SQL. PostgreSQL has many different FDWs, from the built-in postgres_fdw, to others that can read/write to other databases or remote sources. Foreign data wrappers are used to run federated queries (queries across instances), push data into remote systems, and can be used to migrate data to PostgreSQL.
The postgres_fdw lets you work with data across PostgreSQL databases. Since it’s introduction in PostgreSQL 9.3, the postgres_fdw has added features to make it possible to run distributed workloads, including different query pushdowns (executing queries on remote instances), convenience functions for loading remote schemas, and running queries asynchronous across remote instances. While the postgres_fdw is a good solution for certain types of data federation, but is not yet a full solution for sharding, as sharding requires additional data management techniques (e.g., node management / rebalancing).
Using the postgres_fdw in production requires security considerations, including authentication/authorization managemet, including on both the local and remote servers, and network management. I won’t be getting into these techniques here, but if you decide you want to use this in production, you’ll want to follow security best practices. At PGConf EU 2015, I gave a presentation on lessons learned deploying the postgres_fdw in production; most of those lessons still apply!
With partitioning and FDWs, we now have the tools to run distributed pgvector queries!
Distributed queries for pgvector
We can combine partitioning and the postgres_fdw to run pgvector queries across multiple instances. For this experiment, I set up 3 instances:
- Two r7gd.4xlarge (16 vCPU, 128GB RAM) instances. These are called
node1andnode2in this post. - One “head node” that sends the data to the different systems, which I’ll refer to as
head. I used a smaller instance here, as most of the work is handled bynode1/node2.
Additionally, to reduce latency, I kept all of these instances within the same availability zone, and I used the local disk (NVMe) for storage on node1 and node2.
On node1 and node2, I used the following applicable postgresql.conf configuration parameters:
effective_cache_size: 64GBmaintenance_work_mem: 32GBmax_parallel_maintenance_workers: 15max_parallel_workers: 16max_parallel_workers_per_gather: 16max_worker_processes: 32shared_buffers: 32GBwork_mem: 64MB
For all the tests, I used pgvector@0d35a141, which is a few commits off from the code in the v0.6.2 release.
I ran two tests:
- “Can we”: determine if this method is even feasible.
- “Should we”: demonstrate how federation technique impacts recall and query performance using ANN Benchmarks.
Test 1: “Can we” - feasibility of pgvector distributed queries
First, we need to set up the schema on each node. For this test, I ran the following commands on node1 and node2 in a database called vectors with a user called distpgv that has create permissions in that database:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE vectors (
id uuid PRIMARY KEY DEFAULT gen_random_uuid(),
node_id int NOT NULL DEFAULT 1, -- change to 2 on node 2
embedding vector(768)
);
ALTER TABLE vectors ALTER COLUMN embedding SET STORAGE PLAIN;
The following function is used to generate synthetic data:
CREATE OR REPLACE FUNCTION public.generate_random_normalized_vector(dim integer)
RETURNS vector
LANGUAGE plpgsql
AS $function$
DECLARE
a real[];
mag real;
x real;
i int;
BEGIN
SELECT array_agg(random()::real) INTO a
FROM generate_series(1, dim);
mag := public.vector_norm(a::vector);
FOR i IN 1..dim
LOOP
a[i] := a[i] / mag;
END LOOP;
RETURN a::vector;
END;
$function$;
For this test, I ran the following on each instance to insert 5MM rows (2.5MM on each instance):
INSERT INTO vectors (embedding)
SELECT generate_random_normalized_vector(768)
FROM generate_series(1,2_500_000);
Once the inserts were completed, I ran the following to build the index (adjust max_parallel_maintenance_workers to the available cores on your environment):
SET max_parallel_maintenance_workers TO 16;
CREATE INDEX ON vectors USING hnsw(embedding vector_cosine_ops) WITH (ef_construction=256);
With this, the data is now set up on each of the nodes. Back on the head instance, we need to set up the FDW and connections to the instances.
On head, first install pgvector and the postgres_fdw:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
The next set of SQL is the key bit that will allow us to run distributed pgvector queries. You’ll create two “servers,” which will tell PostgreSQL where your remote nodes are, and what their capabilities are:
CREATE SERVER vectors1
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (async_capable 'true', extensions 'vector', dbname 'vectors', host '<NODE1>');
CREATE SERVER vectors2
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (async_capable 'true', extensions 'vector', dbname 'vectors', host '<NODE2>');
Aside from the connection parameters, there are two key options to know:
async_capable: This means that the remote server is capable of executing queries asynchronously. This lets us simultaneously execute pgvector queries on each node, instead of executing them one-at-a-time (serially).extensions: This indicates what extensions are available on the remote server. This allows us to pushdown the pgvector index lookups to the remote nodes.
Next, we need to add connection information for how a local PostgreSQL user will connect to the remote instances. Substitute local_user for the user you create on your local instance:
CREATE USER MAPPING FOR local_user
SERVER vectors1
OPTIONS (user 'pgvdist', password '<SECUREPASSWORD>');
CREATE USER MAPPING FOR local_user
SERVER vectors2
OPTIONS (user 'pgvdist', password '<SECUREPASSWORD>');
Finally, we’ll create a partitioned table, where each partition is a “foreign table,” or a reference to a table located on the remote server.
CREATE TABLE vectors (
id uuid,
node_id int,
embedding vector(768)
)
PARTITION BY LIST(node_id);
-- reference to the table on node 1
CREATE FOREIGN TABLE vectors_node1 PARTITION OF vectors
FOR VALUES IN (1)
SERVER vectors1
OPTIONS (schema_name 'public', table_name 'vectors');
-- reference to the table on node 2
CREATE FOREIGN TABLE vectors_node2 PARTITION OF vectors
FOR VALUES IN (2)
SERVER vectors2
OPTIONS (schema_name 'public', table_name 'vectors');
Let’s test to see that we can query the remote tables. Below is an example of the output from an explain plan that counts all the rows across each node:
EXPLAIN SELECT count(*) FROM vectors;
yields:
Aggregate (cost=2687700.00..2687700.01 rows=1 width=8)
-> Append (cost=100.00..2675200.00 rows=5000000 width=0)
-> Async Foreign Scan on vectors_node1 vectors_1 (cost=100.00..1325100.00 rows=2500000 width=0)
-> Async Foreign Scan on vectors_node2 vectors_2 (cost=100.00..1325100.00 rows=2500000 width=0)
We can see that the PostgreSQL query planner will attempt to perform an “async foreign scan,” which means it will run each query asynchronously on the individual nodes, and then determine the final results on the head node. When I used EXPLAIN ANALYZE, I received the following output that showed the asynchronous execution:
Aggregate (cost=2687700.00..2687700.01 rows=1 width=8) (actual time=5755.761..5755.762 rows=1 loops=1)
-> Append (cost=100.00..2675200.00 rows=5000000 width=0) (actual time=0.603..5415.869 rows=5000000 loops=1)
-> Async Foreign Scan on vectors_node1 vectors_1 (cost=100.00..1325100.00 rows=2500000 width=0) (actual time=0.319..1192.879 rows=2500000 loops=1)
-> Async Foreign Scan on vectors_node2 vectors_2 (cost=100.00..1325100.00 rows=2500000 width=0) (actual time=0.303..1140.443 rows=2500000 loops=1)
Planning Time: 0.169 ms
Execution Time: 5756.769 ms
Now for the big test: running a distributed / federated query for pgvector. First, let’s create some test data. I ran this command using psql to store the query vector in a session variable called v:
SELECT generate_random_normalized_vector(768) AS v \gset
I ran the following query to find the 10 nearest neighbors across all the nodes:
SELECT id, node_id, :'v' <=> embedding AS distance
FROM vectors
ORDER BY distance
LIMIT 10;
which yielded:
id | node_id | distance
--------------------------------------+---------+---------------------
9a88e75f-4a03-4964-9435-f6596087db7f | 2 | 0.20965892220421145
251fe736-e06b-4a30-ad98-10132fd04db6 | 2 | 0.20981185523973567
3d024d54-b01e-468a-9e3b-d0d63a46c599 | 2 | 0.21044588244644724
d03cd294-d6dc-4074-a614-a2514a64a035 | 1 | 0.2111870772354053
9e5db921-c4f7-4bb8-b840-81d1c5fd4d02 | 2 | 0.21178618704635432
c6edadd6-c5d6-4fd3-9f15-8c6b67e01986 | 2 | 0.212410164619098
bc1822aa-3cfd-4614-8a87-d93909e00e49 | 2 | 0.2132984165340187
1563e694-c84e-4ed3-9285-e0f33e5717c5 | 1 | 0.21351215879655328
c5616138-629b-4dac-97be-8da2a031593c | 1 | 0.21449695955189663
6056e8f5-c52a-4f4d-8ca5-3c160d6116d3 | 2 | 0.21495852514977798
with the following execution plan:
Limit (cost=200.01..206.45 rows=10 width=28) (actual time=18.171..18.182 rows=10 loops=1)
-> Merge Append (cost=200.01..3222700.01 rows=5000000 width=28) (actual time=18.169..18.179 rows=10 loops=1)
Sort Key: (('$1'::vector <=> vectors.embedding))
-> Foreign Scan on vectors_node1 vectors_1 (cost=100.00..1586350.00 rows=2500000 width=28) (actual time=8.607..8.609 rows=2 loops=1)
-> Foreign Scan on vectors_node2 vectors_2 (cost=100.00..1586350.00 rows=2500000 width=28) (actual time=9.559..9.566 rows=9 loops=1)
Planning Time: 0.298 ms
Execution Time: 19.355 ms
Success! We can see that we were able to run the distributed query and get the most similarity vectors regardless of node they were on. Based on the timings, we also see that used the HNSW indexes that were available on each instance.
However, on closer inspection, we can see that we didn’t perform an async foreign scan, but executed each statement serially. Currently (based on my read of the PostgreSQL docs and code), PostgreSQL does not support async foreign scans with a “Merge Append” node (e.g., running multiple operations that require merging sort results, such as a K-NN sort). This may not matter if you don’t have many nodes, but could factor into larger, distributed data sets.
Now that we’ve answered “could we,” let’s look at one aspect of “should we” and measure recall across a distributed data set.
Test 2: “Should we” - ANN Benchmarks using distributed queries for pgvector
For the next test, we’ll see how using this federation technique impacts recall and query performance. We want to test recall to ensure that distributing the data does not cause a regression in the quality of the results. Understanding query performance can help provide guidance on if/when we want to use this technique at all. I specifically did not test other aspects of vector storage (e.g., index size) as this was less of a factor in the differences in the environments tested in this example.
In this experiment, we’ll compare the 2-node federated setup in the previous example to a single instance (1-node, using a r7g.4xlarge) set up. I had to make a few modifications to the pgvector test in ANN Benchmarks to support distributed queries, specifically:
- Supporting creating tables and indexes on individual nodes (in this case,
node1andnode2) - Push setting
hnsw.ef_searchdown to individual nodes. As there isn’t a way to federate the values of session variables fromheadtonode1andnode2(or if there is, I didn’t figure it out), I explicitly set the values usingALTER SYSTEMandpg_reload_conf(). - On the
headnode, I created a partitioned table with a hash partitioning method with references to the remote nodes:
CREATE TABLE items (
id int,
embedding vector
) PARTITION BY HASH(id);
-- reference to the table on node 1
CREATE FOREIGN TABLE items_node1 PARTITION OF items
FOR VALUES WITH (MODULUS 2, REMAINDER 0)
SERVER vectors1
OPTIONS (schema_name 'public', table_name 'items');
-- reference to the table on node 2
CREATE FOREIGN TABLE items_node2 PARTITION OF items
FOR VALUES WITH (MODULUS 2, REMAINDER 1)
SERVER vectors2
OPTIONS (schema_name 'public', table_name 'items');
For all tests, I used the following build parameters:
m: 16ef_construction: 256
Below are the results from three different datasets available in ANN Benchmarks (for my thoughts on these datasets, please see this blog post), followed by analysis:
sift-128-euclidean(1MM, 128-dim)dbpedia-openai-1000k-angular(1MM, 1536-dim)gist-960-euclidean(1MM, 960-dim)
Recall is measured from 0 to 1 (0% to 100% relevant results returned). Queries per second (QPS) is measured in how many queries complete per second :)
sift-128-euclidean
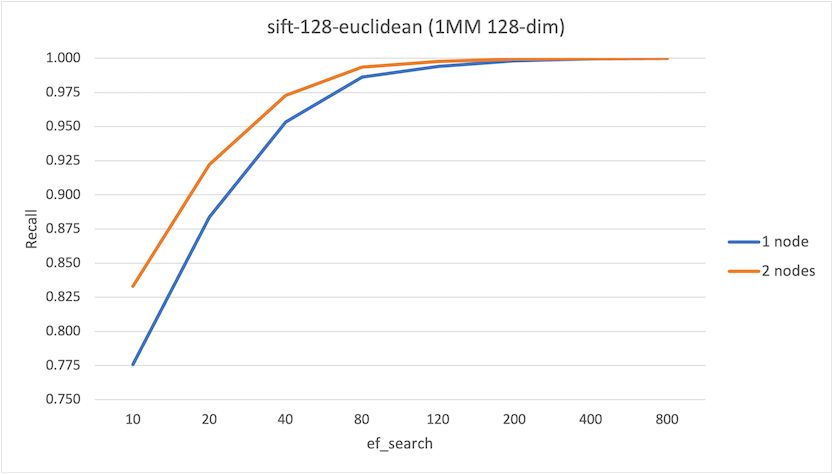
ef_search | Recall (1-node) | Recall (2-node) |
|---|---|---|
| 10 | 0.776 | 0.833 |
| 20 | 0.884 | 0.922 |
| 40 | 0.953 | 0.973 |
| 80 | 0.986 | 0.994 |
| 120 | 0.994 | 0.998 |
| 200 | 0.998 | 0.999 |
| 400 | 1.000 | 1.000 |
| 800 | 1.000 | 1.000 |
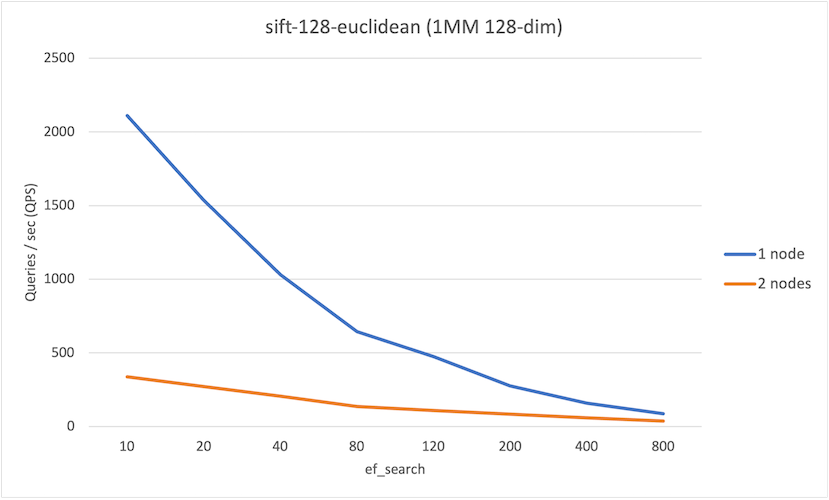
ef_search | QPS (1-node) | QPS (2-node) |
|---|---|---|
| 10 | 2111 | 338 |
| 20 | 1536 | 272 |
| 40 | 1031 | 206 |
| 80 | 644 | 137 |
| 120 | 474 | 109 |
| 200 | 276 | 84 |
| 400 | 157 | 59 |
| 800 | 86 | 36 |
dbpedia-openai-1000k-angular
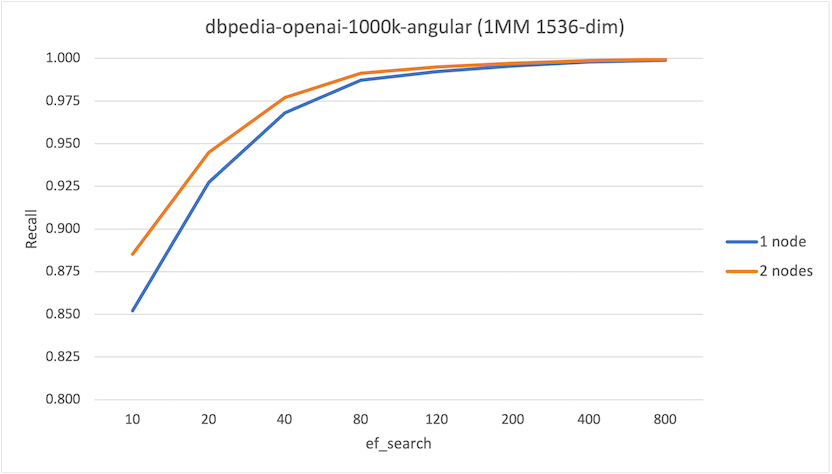
ef_search | Recall (1-node) | Recall (2-node) |
|---|---|---|
| 10 | 0.852 | 0.885 |
| 20 | 0.927 | 0.945 |
| 40 | 0.968 | 0.977 |
| 80 | 0.987 | 0.991 |
| 120 | 0.992 | 0.995 |
| 200 | 0.996 | 0.997 |
| 400 | 0.998 | 0.999 |
| 800 | 0.999 | 0.999 |
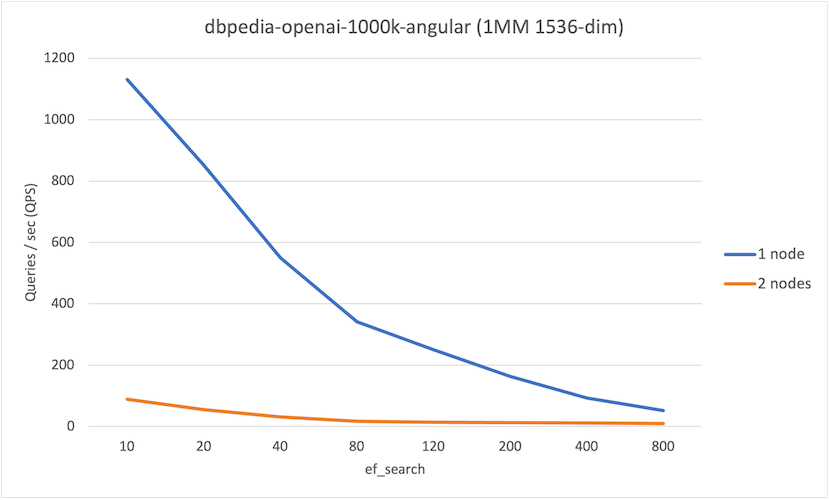
ef_search | QPS (1-node) | QPS (2-node) |
|---|---|---|
| 10 | 1131 | 89 |
| 20 | 853 | 55 |
| 40 | 550 | 31 |
| 80 | 342 | 17 |
| 120 | 251 | 13 |
| 200 | 163 | 13 |
| 400 | 93 | 11 |
| 800 | 52 | 9 |
gist-960-euclidean
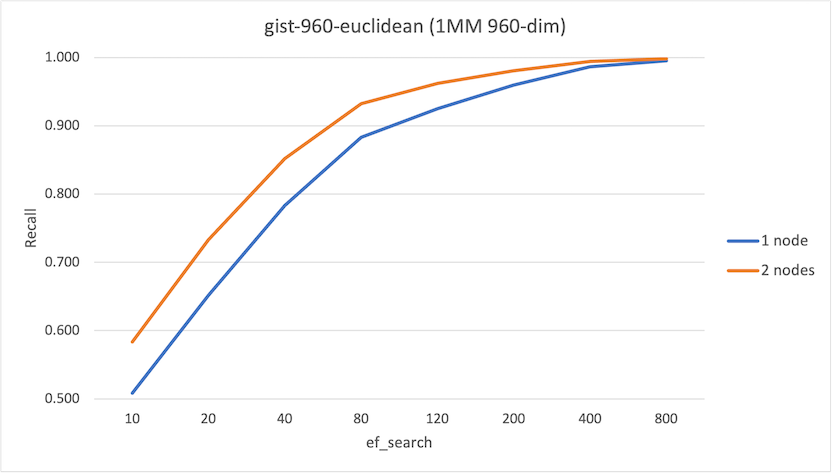
ef_search | Recall (1-node) | Recall (2-node) |
|---|---|---|
| 10 | 0.509 | 0.584 |
| 20 | 0.652 | 0.733 |
| 40 | 0.783 | 0.852 |
| 80 | 0.883 | 0.932 |
| 120 | 0.925 | 0.962 |
| 200 | 0.960 | 0.981 |
| 400 | 0.987 | 0.995 |
| 800 | 0.995 | 0.998 |
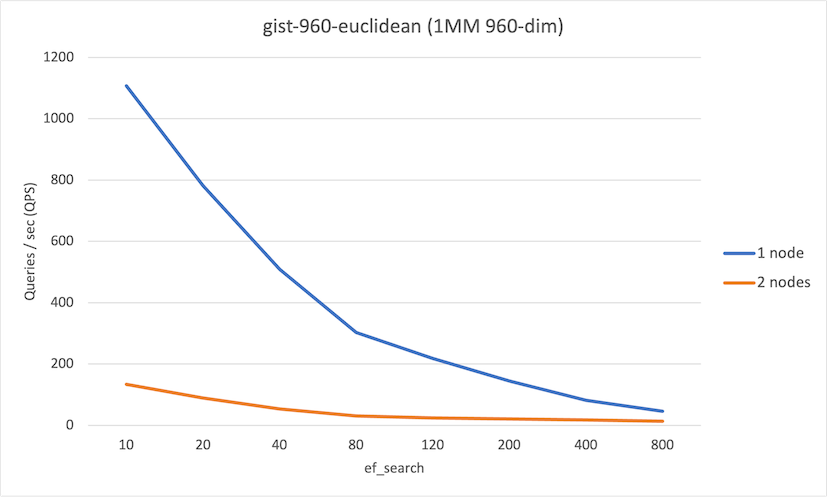
ef_search | QPS (1-node) | QPS (2-node) |
|---|---|---|
| 10 | 1107 | 134 |
| 20 | 782 | 89 |
| 40 | 509 | 54 |
| 80 | 302 | 30 |
| 120 | 218 | 24 |
| 200 | 144 | 21 |
| 400 | 81 | 17 |
| 800 | 45 | 13 |
There are two interesting observations from these runs:
- At lower values of
hnsw.ef_search, we observe an improvement in recall on the 2-node system up to 15%, which is not insignificant. - Overall we observe that QPS on the 1-node system is higher than the 2-node system. This is primarily due to network latency, though the serial execution of each foreign scan may impact (and will impact as the number of nodes in the system increase).
From this, it’d be easy to conclude that the distributed technique should not be used. However, the workload fit entirely into memory on the 1-node instance; if the 1-node was memory constrained and had to continuously fetch data from networked-attached storage, we would see different results.
Below I repeated the 1-node test, but I used the default PostgreSQL settings, including 128MB for shared_buffers. This would memory constraint the system. I still used the local NVMe for storage. You can see the results of this test below:
sift-128-euclidean
ef_search | QPS (1-node; PG defaults) | QPS (2-node) |
|---|---|---|
| 10 | 1030 | 338 |
| 20 | 710 | 272 |
| 40 | 450 | 206 |
| 80 | 266 | 137 |
| 120 | 193 | 109 |
| 200 | 119 | 84 |
| 400 | 69 | 59 |
| 800 | 39 | 36 |
dbpedia-openai-1000k-angular
ef_search | QPS (1-node; PG defaults) | QPS (2-node) |
|---|---|---|
| 10 | 731 | 89 |
| 20 | 510 | 55 |
| 40 | 323 | 31 |
| 80 | 192 | 17 |
| 120 | 141 | 13 |
| 200 | 93 | 13 |
| 400 | 53 | 11 |
| 800 | 30 | 9 |
gist-960-euclidean
ef_search | QPS (1-node; PG defaults) | QPS (2-node) |
|---|---|---|
| 10 | 712 | 134 |
| 20 | 482 | 89 |
| 40 | 306 | 54 |
| 80 | 179 | 30 |
| 120 | 128 | 24 |
| 200 | 81 | 21 |
| 400 | 44 | 17 |
| 800 | 25 | 13 |
Overall, while the 1-node test using the PostgreSQL defaults had higher QPS than the 2-node system, we see that the differences weren’t as large once the workload was memory constrained – and in certain cases, the performance was comparable.
Conclusion
Distributing a workload across multiple databases can be used to further scale a workload once you’re unable to scale it past a single instance. pgvector builds on PostgreSQL features that help with scaling vertically, and recently pgvector releases have also shown that vector workloads can scale on PostgreSQL.
While the experiments in this post show that it’s possible to distribute pgvector workloads across multiple instances – and we can see benefits with recall – there’s additional work that can simplify and help scale pgvector across multiple writable instances (e.g., pushdown session parameters, async execution across “merge append” nodes). If your workloads is read heavy, you can still use read replicas as a way to distribute traffic if your primary instance is saturated, but note that the entire data set is available on each instance.